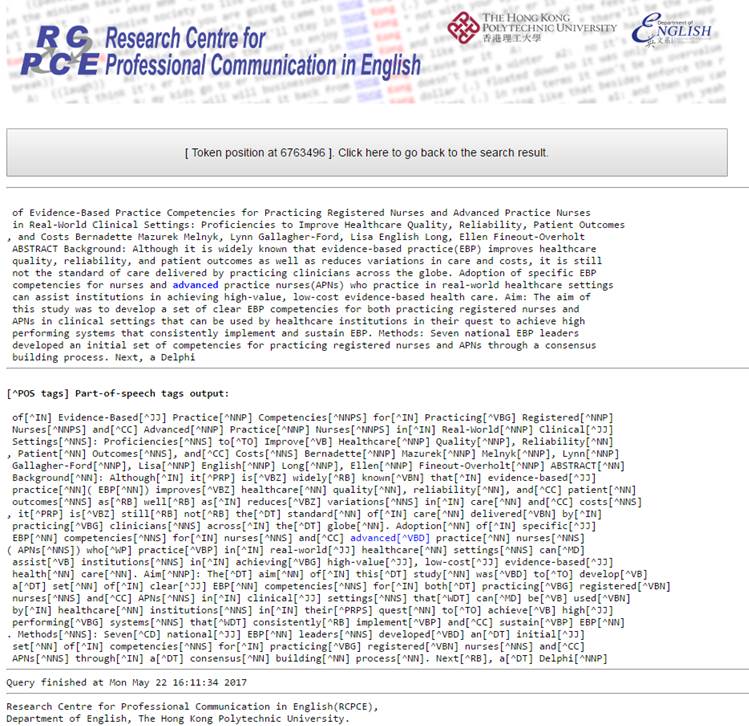
Part-of-speech tag search tutorial
Key features of the part-of-speech search engine
1. Support a search string of up to four query parameters.
2. Support both head and tail partial search of the query word/phrase (e.g. '-ing' will return 'searching', 'interesting', etc.)
3. Support tail partial search for the part-of-speech tag (e.g. ^NN- will include query parameters ^NN, ^NNS, ^NNP and ^NNPS.)
4. Can instruct the search engine to skip an exact number of words in between two search parameters.
5. Coloured concordances, with query parameters highlighted in colour in the concordance list.
6. Concordances can be downloaded in Rich Text format, which retains the colors in each concordance line and can be opened in Microsoft Word and Windows WordPad for further analysis or editing.
7. Support concordance lines sorting on:
i. the keyword and its part-of-speech tag (the first parameter in the query string),
ii. the words and their part-of-speech tags of the first 5 words on the right-hand side of the keyword,
iii. the first word and part-of-speech on the left-hand side of the keyword.
8. Sort by the field, discipline and type of the article of a concordance.
9. Expanded view of a concordance line of up to 200 words in a section.
10. Full description of the part-of-speech tags shown as tooltips over the tags when the cursor points to it.
11. A maximum of 10,000 instances can be listed. If there are more than 10,000 instances, the system will randomly pick 10,000 instances for display.
12. Penn Treebank part-of-speech tags.
13. Part-of-speech tagging with Stanford Part-of-Speech Tagger.
What is a query parameter?
A query parameter is a unit of text that has a string and/or a part-of-speech tag and is separated from another string with a space. For example, the following query string contains four search parameters:
word1 word2 word3 word4
A parameter contains two parts:
word^pos
For example, cat^nn is one parameter, cat is the word, nn is the POS tag. The caret ^ separates the word and the POS tag.
The Stanford Part-of-Speech tagger was used to tag the corpora; Penn Treebank project part-of-speech tags are used for query.
The search engine supports a partial search. You can put a dash at the head and/or the tail of the query word/phrase, and add the dash to the tail of the part-of-speech tag for querying words/part-of-speech tags that match the pattern. For example:
-ment
will list all words that end with ment. (e.g. development, advancement, etc.)
-fin-
will list words that contain fin (e.g. refinement, define, etc.)
^NN-
will list words that have a part-of-speech tag that starts with NN (e.g.
^NNP, ^NNPS)
The search engine is case-insensitive. Punctuation is not accepted.
n-gram
To search for an n-gram, just type the word in the query parameter box and click query.
skipgram
You can insert a skipgram parameter in the query string to perform a skipgram search. The skipgram parameter starts with a caret ^, followed by an one-digit number to specify the number of words to skip. For example:
He ^3 work
will return:
He is going to work
He never goes to work
He cannot go to work
How to use:
On the corpus page, type in query parameters and select the number of instances to be listed. Click 'Click here to query' button to start the search.
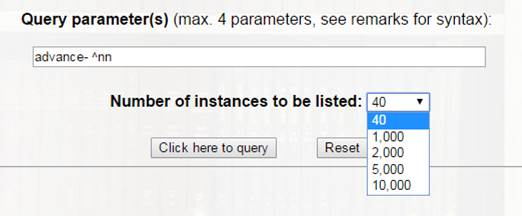
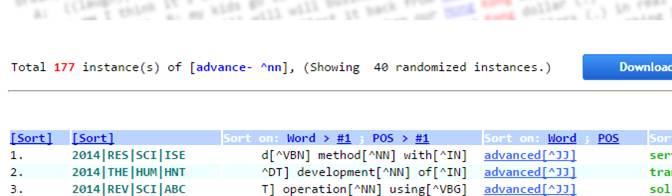
The top left of the search result list tells you the number of all matched occurences in the corpus. If the list is truncated to match the maximum number of instances limited by the system or specified in the query, a reminder 'Showing XX randomised instances' is displayed.
If the query returns fewer instances as set by the query option than the corpus contains, the link below will appear on the top right side of the query result:

You can click the link to show all instances.
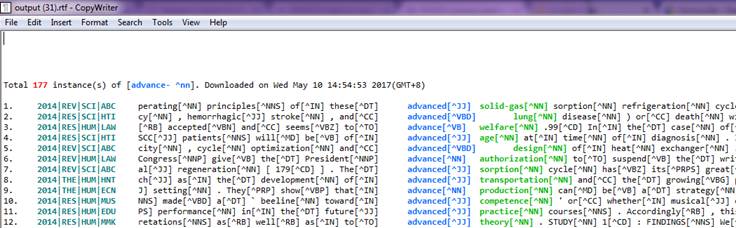
Download the concordance list
On the top right side of the search result list, a blue button with the caption

appears after the full list is completely loaded. The downloaded Rich Text format file retains the colours of the concordance list first displayed. You can use Microsoft Word or free software such as WordPad for Windows and CopyWriter to open a Rich text format file.
Sort the concordance list
On the header of the concordance list, you can click the specific sorting option to sort the list. The Rich Text formatted file retains the original concordance list and is not affected by sorting.

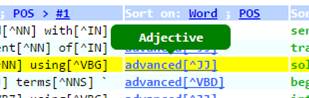
Show the full description of a part-of-speech tag
You can place the mouse cursor on any part-of-speech tag to show the full description of the tag. A list of all part-of-speech tags used is attached to the end of the concordance list.
Show the expanded section of a concordance line
You can click on the first query word (i.e. the word underlined and in blue) to load the expanded section of the concordance line:

The expanded section contains the original text and the part-of-speech tagged text. The first query word is highlighted in blue.