ConcGram©
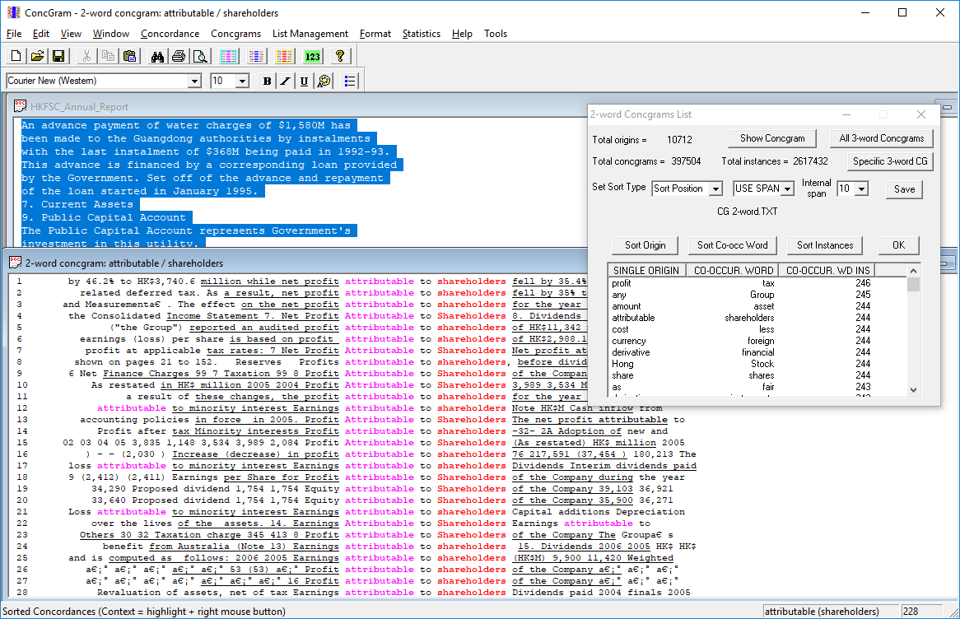
The original ConcGram software was developed by Chris Greaves (2005) and is distributed with John Benjamin's book or order it online. ConcGram was designed to automatically search for concgrams and their frequency in a corpus which facilitates a truly 'corpus-driven' methodology. Unlike ngrams or skipgrams, concgrams shows both constituency (AB, ACB) and positional (AB, BA) variations (Cheng et al. 2006). The original ConcGram is a closed source software which was designed in the year of 32-bit Microsoft Windows. The 32-bit system limits the maximum amount of computer memory the program use, and restrains ConcGram from effectively handling a large corpus.
To know more about concgramming, please read the paper written by Professor Winnie Cheng, Mr Chris Greaves and Professor Martin Warren.
Click here for ConcGram demonstration on YouTube.
ConcGramCore[BETA]
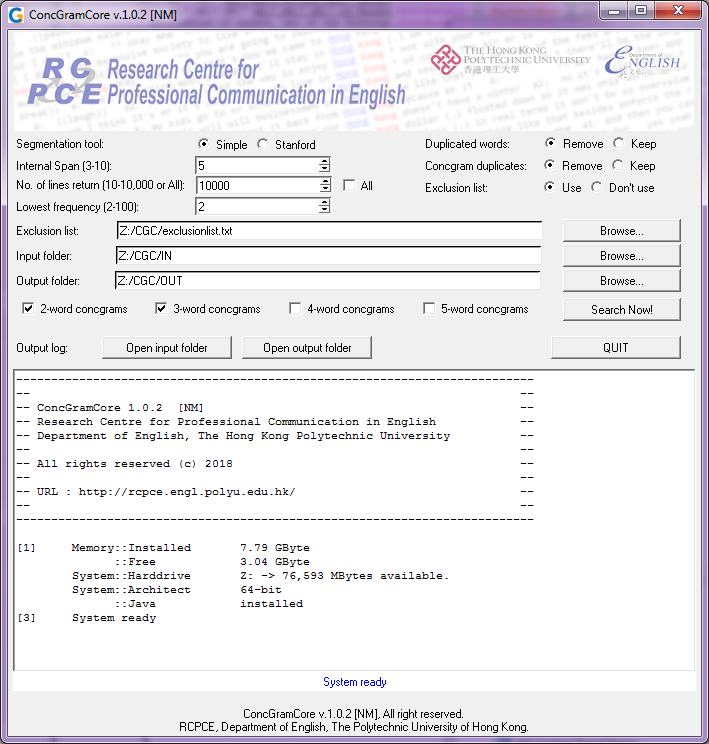
RCPCE rewrote the core automatic concgram identification feature of ConcGram and named the new software as ConcGramCore in March 2018 for teaching and research purposes.
ConcGramCore utilised the SQL query engine of SQLite3 and Strawberry Perl (v.5.24) for the automatic concgram search process and is much more efficient to identify concgrams in a large corpus. The codes can be modified to run on Linux and Apple computers. The program was not designed to be the fastest but to allow simple maintenance and scalability. The core identification process is handled by SQLite which is a robust and well-maintained engine to get the job done. More importantly, all these technologies are free and still widely used (and supported).
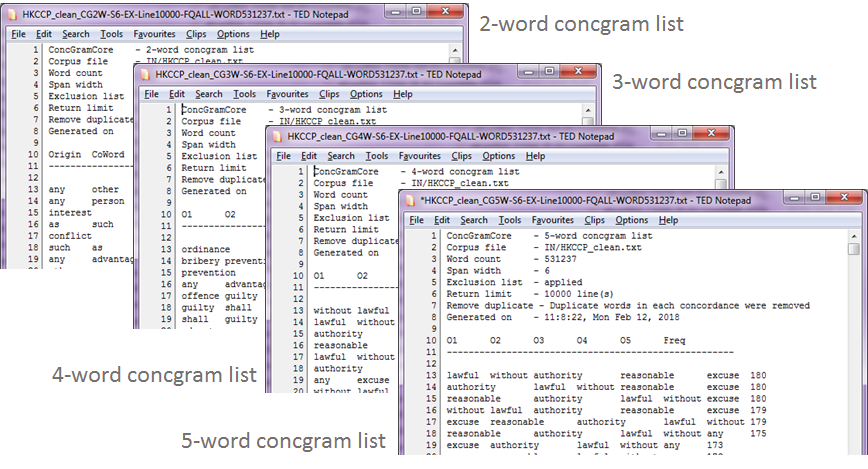
ConcGramCore users can also have the options to select the desire segmentation methods. A simple segmentation method separate English words by punctuations, white spaces and paragraph marks. ConcGramCore also utilises the Stanford Part-of-Speech Tagger engine for more accurate segmentation and for compatibility to handle segmentation of other languages such as Arabic and Chinese (with modifications on the code). ConcGramCore processes corpora in batch. The output is saved automatically.
ConcGramCore runs on 32-bit and 64-bit Microsoft® Windows computer with 4GB or more memory installed. As the engine will use your harddisk space to swap the concgrams it found, the faster the harddisk, the better. Minimum 250GB free spaces and 4GB computer memory are recommended for a wide span search on a multi-million words corpus.
You will still need ConcGram or other corpus software (e.g. AntConc) to lookup the concgrams concordances that ConcGramCore found.
| Item | Description | Click to download |
|---|---|---|
| 1. | What is concgram? [Quick check] | pdf |
| | ||
| 2. | Download ConcGramCore v.1.0.2 (GUI) [version history] | ZIP file |
| 3. | Setup instruction | pdf |
| 4. | User manual | pdf |
| | ||
| 5. | Java 8 SE Runtime Environment [Required for segmentation with the Stanford POS Tagger] |
link |
| 6. | FAQ | link |
| | ||
| 7. | Source code (MIT License) | Zip |
| | ||
| 8. | Download and install demonstration | YouTube video |
| 9. | Running ConcGramCore demonstration | YouTube video |
| |
|
You can run the self-extracing executable CGC-1.0.2.exe and extract files to the root directory of your drive (e.g. D:\CGC\ ). After extraction, please run CGC.bat in the program directory (e.g. D:\CGC\ ) to start the software. You can run CGC64GUI.exe (for 64-bit Microsoft Windows) or CGC32GUI.exe (for 32-bit Microsoft Windows) directly if you know which Windows version that you are using. If you want to use the Stanford POS tagger for segmentation, please install the Java 8 SE Runtime Environment (JRE).
If there are questions on ConcGram or ConcGramCore, please feel free to contact us at engl.rcpce[at]polyu.edu.hk. |
Last updated on 22 November 2018